No More Hustleporn: A short guide to engineering better GPT-3 prompts.
Tweet by Varun Shenoy
https://twitter.com/varunshenoy_
@varunshenoy_:
A short guide to engineering better GPT-3 prompts.
Here's how I redesigned GraphGPT's prompt to become faster, more efficient, and handle larger inputs:
@varunshenoy_:
Some quick background:
GraphGPT is a tool that generates knowledge graphs from unstructured text using OpenAI's GPT-3 large language model.
twitter.com/varunshenoy_/s…
@varunshenoy_:
Can LLMs extract knowledge graphs from unstructured text?
Introducing GraphGPT!
Pass in any text (summary of a movie, passage from Wikipedia, etc.) to generate a visualization of entities and their relationships.
A quick example:
@varunshenoy_:
Let's take a look at the original prompt.
This is a one-shot prompt. We share one example of what a graph might look like after processing a sample prompt.
Note how the entire state of the graph is stored within the prompt.
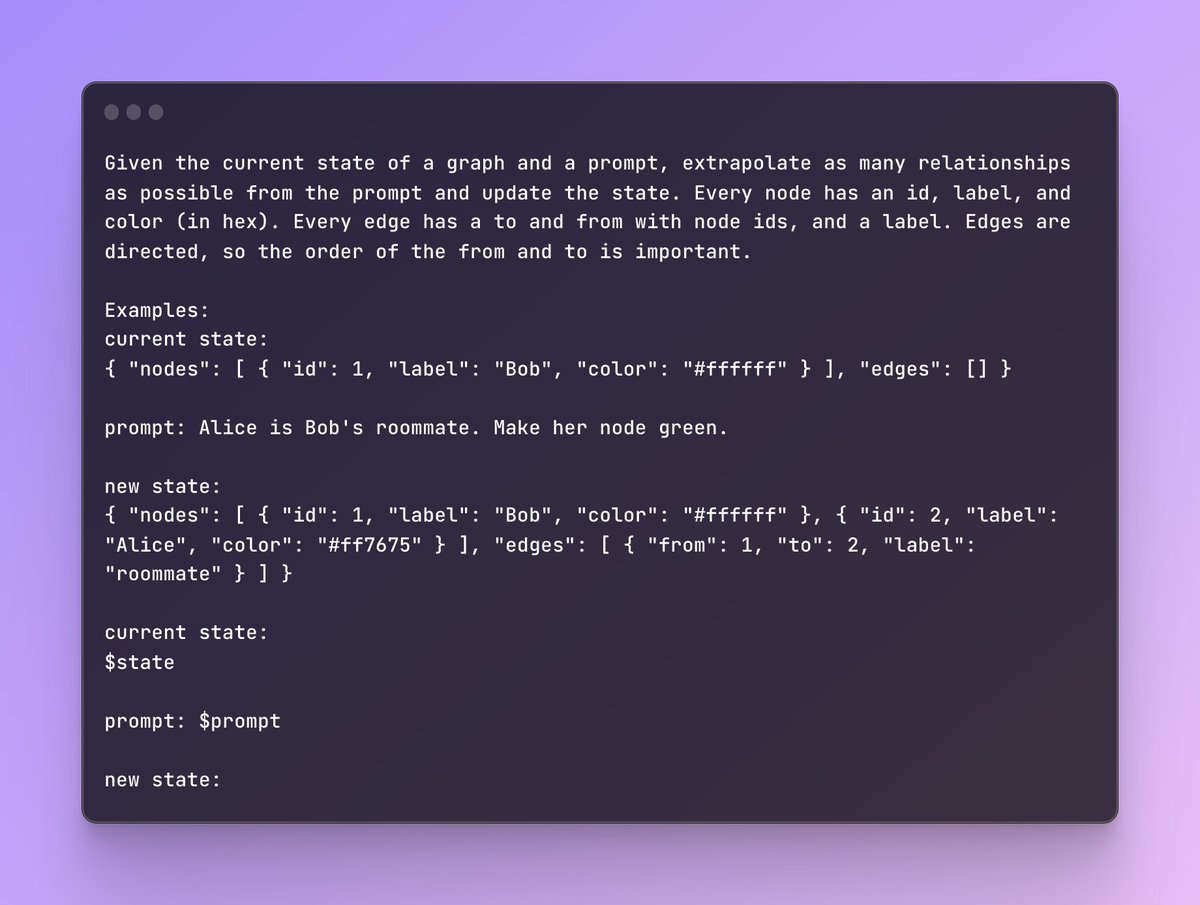
@varunshenoy_:
While this is fine for most cases (especially for a weekend hack), it comes with some issues.
It's expensive! On every successive query, you have to pass the state as an input and receive an updated state as an output.
@varunshenoy_:
It's also slow. GPT has to generate many repeated tokens for the state at the output.
There's a lot of redundancy in our state between prompts!
Finally, if your graph is large, you can run into limits imposed by MAX_TOKENS or context window size.
@varunshenoy_:
In sum: maintaining state within a prompt is costly.
Ideally, we want a set of instructions we can carry out on the client side to update the state within the browser.
GraphGPT's new prompt is entirely stateless.
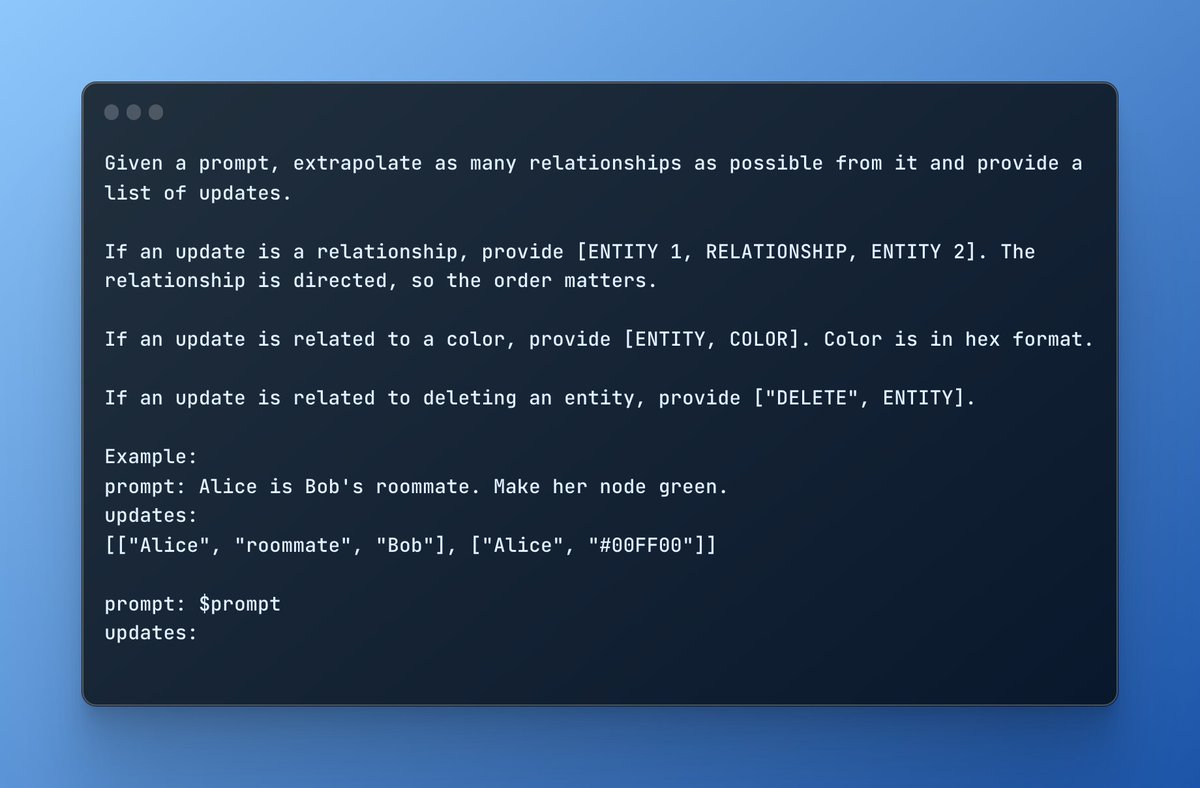
@varunshenoy_:
In the prompt, I teach a simple domain-specific language (DSL) to the model.
I restrict the model to three kinds of updates: identifying relationships, updating colors, or deleting entities.
This is the power of in-context learning!
@varunshenoy_:
Our state is now entirely maintained within the browser. GPT generates far fewer tokens, improving costs and latency.
All we have to do is parse our DSL on the frontend and update our local state.
@varunshenoy_:
We can now maintain much larger graphs and process massive chunks of text quickly.
In effect, we've saved time and money by being clever with how we manage state between our personal computer and GPT.
@varunshenoy_:
Interested in seeing the rest of the project?
Here's the repo for GraphGPT:
github.com/varunshenoy/Gr…